sequenceDiagram Client->>MQTTBroker: Subscribe test-prefix/dev-123456/response/+ Server->>MQTTBroker: Subscribe test-prefix/dev-123456/request/+ Client->>MQTTBroker: Send to test-prefix/dev-123456/request/123, call "example-method" MQTTBroker->>Server: Forward data to test-prefix/dev-123456/request/123 Server->>Server: Dispatch call to method "example-method", handle it Server->>MQTTBroker: Send reply to test-prefix/dev-123456/response/123 MQTTBroker->>Client: Forward data to test-prefix/dev-123456/response/123
QoS has three levels, represented by 0, 1, and 2, with the following meanings:
QoS 0: At most once, similar to UDP packets, send it and don’t guarantee delivery. This is the simplest service level and may lose messages. Due to its high performance, this level is suitable for periodic sensor data reporting.
QoS 1: At least once, this means the message will be sent at least once, even in unstable network conditions, ensuring the message arrives. It has slightly poorer performance and is suitable for scenarios where duplicates are handled (redundant data processed at the receiver’s end) but reliable delivery is needed.
QoS 2: Exactly once, this is the highest level, ensuring the message neither gets lost nor duplicates (although nothing is absolute, there is still a chance of data loss). Obviously, this method’s performance is the worst and is suitable for scenarios where strict requirements on message duplication are necessary, such as in aerospace.
In common home, office, and industrial IoT scenarios, we mostly use QoS levels 0 and 1. QoS 2 is less used due to poor performance, and for important data scenarios, we can simply handle duplicate data on the receiver’s end, which greatly improves performance. Additionally, we can use QoS 0 and implement our own message retransmission mechanism at the application layer to ensure no message loss.
Furthermore, besides QoS 0, the other two levels require client storage for message retransmission mechanisms. Therefore, if there are multiple client instances locally, it is necessary to allocate different storage areas for them to avoid conflicts and errors.
For example, in paho.mqtt.golang, MemoryStore is used by default as the Store. However, if you use its FileStore, you need to specify different folder paths to solve this problem.
Session Persistence
Session persistence means that after a client disconnects, it can resume the previous session state instead of losing all unprocessed messages. Obviously, this is very important for IoT devices that need to be connected to the network for a long time and may be in very poor environments. Session persistence allows the device to resume from where it was disconnected upon reconnection, preventing duplicate data processing and data loss.
This feature is related to the CleanSession configuration, and its principle is easy to understand. The Broker confirms whether the client needs to maintain a session, i.e., whether CleanSession=false is set, during client connection. When a session is maintained, the Broker stores the following information:
Session information itself, including some connection parameters;
Client subscription information;
Messages:
QoS 1&2 messages not confirmed by the client;
QoS 1&2 new messages when offline;
QoS 2 messages not completed confirmation;
Meanwhile, the client also stores messages outside QoS 0:
QoS 1&2 messages not confirmed by the Broker;
QoS 2 messages not completed confirmation;
Obviously, since paho.mqtt.golang uses MemoryStore by default, you need to pay special attention to changing it to FileStore.
Retained Messages
This feature is often misunderstood and misused. Many people mistakenly believe it is used for storing messages, but in fact, retained messages ensure that each topic only keeps the latest message.
Retained messages are set during sending to tell the Broker whether the current message needs to be retained. We can see from the code that retained is the third parameter sent, which we usually set to false, setting it to true when needed.
Device status updates: For example, a light controller in a smart home system publishes a status update message, and all clients subscribing to this topic (like mobile apps or other controllers) can immediately know the current status of the lights, and importantly, the device’s online/offline status;
Notification systems: In a notification system, when a new notification is published, retained messages ensure that all online users can see the latest notification immediately, without waiting for the next heartbeat check or subscription update.
Considerations:
As with offline messages with QoS 1&2, be careful when subscribing to topics with retained messages. If you subscribe to a bunch of topics that have retained messages, at the moment of successful subscription, a large amount of messages will be sent from the Broker (this also depends on the Broker, as they often limit the number of retained messages for subscribed topics);
If you want to delete retained messages, send an empty message to the same topic. Generally, unless you sent a message incorrectly marked as retained, you do not need to delete it, as the later message always overrides the previous one.
Last Will Message
Last will messages, as the name suggests, are messages left by the client after it goes offline. Simply put, it is a feature set by the client that allows the Broker to send a specified message to a specified Topic when it detects the client’s disconnection. Its most suitable application scenario is sending an offline message to a relevant Topic when the client disconnects, and other clients just need to subscribe to this Topic to get timely notifications of other clients going offline.
In paho.mqtt.golang, the connection configuration parameters involved are as follows, just as one sets a will before passing away, in MQTT protocol, the last will is set at the time of connection.
You can see that the required parameters are the same as for a normal message. If combined with Retained, you can easily implement device online/offline notification messages. However, keep in mind that the configured message is actually completed by the Broker on behalf of the client, since the client is offline when this message is sent.
Keep Alive Protocol and Client Takeover
This is actually to address the ‘half-open’ problem of TCP, where ‘half-open’ means that theoretically, TCP itself has a disconnection notification mechanism, but in practice, it often happens that one side disconnects without notifying the other. In the MQTT protocol, this used to occur frequently with mobile or satellite connections, but nowadays, it is more common with IoT devices disconnecting due to power outages.
Therefore, the MQTT protocol includes a KeepAlive option, so the client needs to negotiate a heartbeat cycle with the Broker to check if the other party is online. During this cycle, if there are message exchanges between the client and the Broker, there is no need to send a heartbeat packet. However, if there are no other message exchanges within this cycle, the client must send a heartbeat packet to tell the Broker that it is still online. Correspondingly, if the Broker does not receive a heartbeat packet within one and a half heartbeat cycles, it can consider the client offline and actively disconnect. Similarly, if the client does not receive a heartbeat reply packet from the Broker within a reasonable time frame (i.e., PingTimeout), it also needs to actively disconnect.
Have you noticed a problem? If the Broker does not disconnect the client connection, for example, the heartbeat cycle is very long, but the TCP connection is already half-open, and the client is already reconnecting, does it mean that multiple TCP connections between the client and the Broker might occur? But in reality, this will not happen because in the MQTT protocol, a ClientId is required, and the same ClientId can only maintain one connection with the Broker at most. The later connection will take over the previous one, i.e., kick the previous connection offline.
You can see from its source code that the default heartbeat cycle is 30 seconds, and the heartbeat timeout is 10 seconds.
Conclusion
Overall, these features of the MQTT protocol enable it to efficiently support various IoT application scenarios, including resource-constrained remote devices, unreliable network environments, and real-time data distribution. Understanding and using these features correctly helps to build more reliable and efficient IoT systems.
At the same time, I believe that with a better understanding of the protocol details, you can be more professional when using this protocol and avoid some common mistakes:
When implementing a client, interfacing with the server:
Considering Retained as data that the server needs to retain;
Ignoring the scenario and setting the QoS of all sent messages to 2;
When implementing a server, interfacing with a client:
Requiring the other party to implement an application-layer heartbeat protocol;
Blaming the other party for sending messages too frequently, with the client explaining that it reports messages at most once a minute (here’s a homework assignment for you, why?);
We’ve only discussed the features of MQTT v3.1.1 this time. In fact, MQTT also has v5 features, which I will continue to explain next time.
This article is licensed BY-NC-SA Author: 习之北 (@xizhibei) Original link: https://blog.xizhibei.me/en/2024/05/02/mqtt-4-features/ ]]><p>In <a href="/en/2021/12/11/mqtt-3-sub-pub-and-topics/">our last article</a> (which feels like ages ago :P), we discussed MQTT’s publish-subscribe functionality. This time, let’s go straight into its features.</p>【MQTT 系列】(四)v3.1.1 特性https://blog.xizhibei.me/zh-cn/2024/05/02/mqtt-4-features/2024-05-02T12:44:51.000Z2024-07-11T14:33:27.064Z在上次的文章中(似乎有那么亿点久了 :P),我们说了 MQTT 的发布订阅相关的功能,这次我们直接来说它的特性。
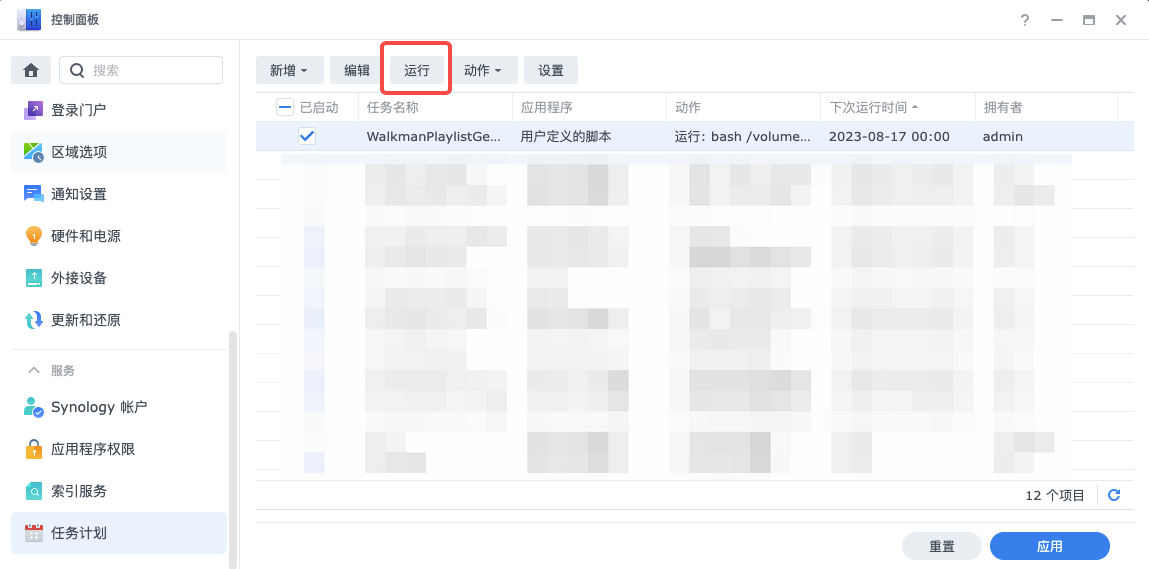
扫码配置与升级:这是个非常有趣且实用的功能,背景是我们的设备没有加触屏,需要客户进一个网络的 Web 后台配置,导致客户配置机器非常麻烦,而且终端部署的地方不一定有人会操作,客户有时候需要开车几百公里去操作。我思考过好多解决方案,突然某天看着扫码器发呆了好久,灵感就来了(可能这就是所谓的「念念不忘,必有回想」),二维码不就是个信息输入载体么?既然可以把健康码作为二维码信息,当然也可以把配置信息作为二维码信息,其中当然还可以包含升级链接,于是花了两天做出了 Demo ,大家试用了之后,一致觉得非常有用,于是推给客户用,没想到过了两周,他们几乎完全放弃了进入后台配置的方式,毕竟扫个码那么简单的事情方便太多了。这样做了之后,可以让我们针对不同的客户需求,制作不同的升级二维码与配置即可,能够让我们非常快速地迭代软件,对接各地平台的时候最快可以在半个小时的时间内给到客户,并且升级部署成功。
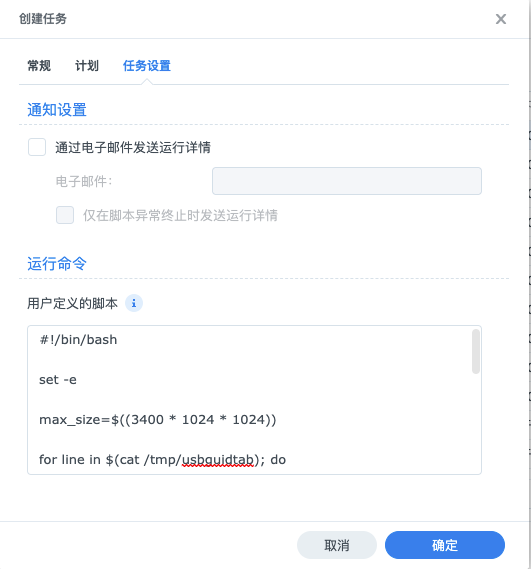
music_dir_size=$(du -sb $music_dir | cut -f1) if [ $music_dir_size -lt $max_size ]; then echo"音乐源目录 $music_dir_size 小于设置的最大值 $max_size ,将最大值设置为 $max_size" max_size=$music_dir_size fi
for line in $(cat /tmp/usbguidtab); do usb_dev=$(echo"$line" | cut -d= -f1)
mount_root=$(mount | grep "$usb_dev" | awk '{print $3}') if [ ! -d "$mount_root" ]; then echo"跳过:$usb_dev 非U盘储存设备,或者挂载失败,可尝试插拔" continue fi
echo"USB device $usb_dev mount on $mount_root" walkman_capability_file="$mount_root/$marker_filename" if [ ! -f "$walkman_capability_file" ]; then echo"跳过:$mount_root: 标记文件 $marker_filename 不存在" continue fi
walkman_music_dir="$mount_root/$dest_dirname" if [ ! -d "$walkman_music_dir" ]; then echo"跳过:$mount_root: 目的地文件夹 $dest_dirname 不存在" continue fi
P.P.S. 这个脚本已经改了几个版本,目前能支持自动检测插入 U 口的设备,并且可以支持多个,功能还是比较简陋的,目前在我的使用习惯下勉强凑合了,有能力的同学修改下这个脚本,就能支持把追更的最新播客,有声书,相声(游泳时听郭德纲,想想就挺带感的。。。)之类的音频也放进去,显然在遇到这种经常需要更新音频的情况下,这个流程就显得更契合了。
什么是战略呢?就是一个团队里面,不能所有人都埋头顾着眼前的事情,一定要有人看着前方的道路,花时间解决重要而不紧急的问题,紧急不重要的事情少做,或者交给别人去做。就如打游戏冲关一般,你不能光顾着打虾兵蟹将,不然只会被无穷无尽的它们给淹死,你的最终目标是打败 Boss 后通关,因此你需要在路上不断积累能够打 Boss 的资源与能力。因此如果你是一个团队在冲关时,一定有人要负责制定打 Boss 的计划,管好分工协作。
Following up on the last introduction (this blogger really drags out the updates :P), let’s discuss some basic concepts of MQTT.
Basic Concepts
In the very simple MQTT Hello World last time, we actually touched on a very important concept: publishing and subscribing.
It’s easy to recall from design patterns, indeed, MQTT fundamentally implements an architectural publish-subscribe pattern.
Let’s recall, where’s the benefit of the publish-subscribe pattern? Decoupling. If the observer pattern is a low coupling between sender and receiver, then the publish-subscribe pattern completely decouples them.
Difference from Message Queues
Then what comes to mind are the various message queues in distributed applications (such as ActiveMQ, RabbitMQ, RocketMQ, Kafka, etc.), and it’s easy to mistakenly think that they are similar, but their application scenarios and ranges are completely different.
First, it’s important to understand that MQTT is just an application layer protocol, comparable to the AMQP protocol in message queues, with MQTT Broker corresponding to various message queues.
Cloud message queue middleware communication protocols are more complex and do not need to consider complex network conditions, but MQTT is much simpler and requires less memory and network resources;
Cloud message queue middleware communication protocols need to store messages, which will be stored indefinitely without client subscriptions, serving purposes like message buffering and smoothing peaks and valleys, whereas MQTT does not store messages, directly discarding them if there are no subscribers;
MQTT clients will receive messages as long as they subscribe to a topic with data, but this is not necessarily the case with message queues, not only do the queues need to be created first, but in the case of multiple clients subscribing to the same queue, each message will be received by only one client;
At this point, they can actually be used in combination, such as devices transmitting data to servers via the MQTT protocol, then placing it into message queues for caching to prevent data loss if the server cannot process timely.
Speaking of which, actually, ActiveMQ supports MQTT, and RabbitMQ also supports MQTT, see more details in MQTT Adapter.
Topic
Topics in MQTT are easy to understand, you can think of them like paths in HTTP protocol or Linux, but you need to remove the first “root directory” because it represents an empty root directory in MQTT.
You can send any data to any topic if you have the permission, and you can also subscribe, but note three symbols:
‘+’ represents a single-level directory match, it can only be placed between directories, not combined with other characters;
Valid examples:
a/b/c/+
a/+/c
a/+/c/+/e
Invalid examples:
a/b/c+
a+
a/+b
‘#’ represents a multi-level directory match, it can only be the last part of a subscription topic, if there is content before it, it must have a ‘/‘, you can also think of it as subscribing to all topics with its preceding content as a prefix;
Valid examples:
a/#
a/b/c/#
Invalid examples:
a#
#a
#/a/b
‘$’ is a reserved prefix for internal topics, even if you subscribe with a single ‘#’, the Broker will not send them to you unless you explicitly subscribe, like the common $SYS topics;
Additionally, aside from testing, try not to subscribe to the ‘#’ topic, as it’s likely to cause problems when the client sends too much data.
Example
Before continuing, it’s best to set up your own local test Broker to avoid interference from other people’s messages on public servers.
Below, we’ll use Go as an example to demonstrate message publishing and receiving.
The most commonly used library currently is paho.mqtt.golang, which can be obtained directly by using:
1
go get github.com/eclipse/paho.mqtt.golang
As an MQTT client, the first thing to do is establish a connection.
c := mqtt.NewClient(opts) if token := c.Connect(); token.Wait() && token.Error() != nil { panic(token.Error()) }
defer c.Disconnect(250)
time.Sleep(time.Second)
In the example above, we established a connection with the simplest options and disconnected after a second. If you’re interested in the options here, you can see MQTT Client options, where the default options are clear at a glance.
Next is publishing and subscribing, below is a very simple example:
Alternatively, you can also try linking publishing and subscribing as mentioned in the first article, such as sending data on the program and receiving on the desktop client, and vice versa.
Finally
In this introductory article, we omitted connection parameters, as well as QoS and Retained two parameters during publishing and subscribing, which are very important details. They will appear in future articles (rest assured, we will let your descendants notify you of updates 🙈).
In my last introduction, I briefly mentioned how to use a public Broker for testing. Obviously, you can’t use a test server as a production environment server; you need one of your own.
Mosquitto
Mosquitto is arguably the most famous open-source MQTT Broker, with just enough functionality. Some advanced features like permission management require the installation of plugins, or even custom plugin development to extend its capabilities.
Installing it is very straightforward, just install the appropriate package, for example, on Mac brew install mosquitto, and on Linux sudo api install mosquitto. If you prefer Docker, the official image is eclipse-mosquitto. I’ll skip the running details and focus mainly on its configuration1:
Listening on the default unencrypted port 1883:
1
listener 1883 0.0.0.0
If you don’t want to configure user password login, here you can configure to allow anonymous connections, meaning no user password:
1
allow_anonymous true
But if you configured to disallow anonymous access, then you need to set up username and password. The user password in this file can be configured using the tool provided by mosquitto: mosquitto_passwd mosquitto/config/pwfile username, and then follow the prompt to enter the password.
Additionally, you need to add this line in the configuration file:
1
password_file /mosquitto/config/pwfile
Furthermore, if you need to restrict permissions for each user, you need to configure an ACL:
1
acl_file /mosquitto/config/aclfile
This configuration is simple, it supports three syntaxes:
topic [read|write|readwrite|deny] <topic>, this can set permissions for anonymous client topics;
user <username>, this is used in conjunction with topic permissions;
pattern [read|write|readwrite] <topic>, this can be used for individual user permissions, where <topic> can contain %c representing the logged-in Client ID and %u representing the username;
Allow anonymous users to read all user-level topics:
1 2
topic read # topic read $SYS/broker/messages/#
Allow user ‘web’ to read all topics:
1 2 3
user web topic read # topic read $SYS/#
Clearly, this level of permissions only satisfies the most basic requirements. If you need to integrate with your platform to implement dynamic login authentication, you would need to use an auth_plugin. One officially recommended plugin is mosquitto-go-auth.
Clustering
Mosquitto itself does not support cluster deployment, but it can be implemented through the backend, see MQTT server support for details.
TLS Certificates
With increasing national requirements for privacy protection, encrypted transmission is becoming an increasingly important component, meaning all personal information transmission must be encrypted.
For MQTT, HTTPS certificates can be used because fundamentally, they are both TLS certificates and thus can be applied to MQTT as well.
If you use a certificate issued and signed by an authoritative CA, simple configuration would be:
But if using a self-signed certificate, the client connection process is a bit more complex, requiring proper CA configuration.
Like HTTPS mutual authentication, MQTT can also use mutual authentication. In this case, when a client connects, the server will require the client to provide a certificate and use your configured CA certificate to verify the client certificate’s signature.
Once setup is complete, you can perform simple tests using a client. However, after a basic test, most people might think it’s ready for full use, but you can do more to ensure reliability.
For instance, you might estimate the number of client connections you need, the number of messages, concurrency, and message sizes to get a general range, and then perform benchmark testing.
I used the MQTT benchmarking tool, which easily tests the stress your newly setup Broker can handle.
It’s fairly user-friendly; if you’ve used HTTP benchmarking tools like Apache Bench, you’ll quickly get the hang of it. For example, from its homepage, a typical scenario is 10 clients, each sending 100 consecutive messages:
In the output, you’ll see the results of the test and can identify potential issues that were not apparent during setup. Although spending an extra hour or two might seem wasteful, discovering these issues after some usage would cost much more than these additional hours. Plus, I believe the difference between engineers isn’t just in speed but in such professional diligence.
P.S.
You could also consider using a paid service to avoid maintenance labor and server costs. For instance, you could choose commercial Brokers like China’s EMQX and international HiveMQ. They support both commercial and open-source versions, and you can either set up on your own servers or use their provided servers. Being commercially supported, they offer more robust features and generally a better experience.
它的安装非常简单,直接安装相应的程序即可,比如在 Mac 中 brew install mosquitto,而在 Linux 中 sudo api install mosquitto。如果想用 docker 也是类似,目前官方的镜像是 eclipse-mosquitto,运行细节,这里掠过,主要说说它的配置1:
Over the past two months, I’ve practically stopped updating, although I’ve mentioned before that updates would not be timely, but it’s the first time it’s been delayed this long. I could excuse it by saying I’m busy, especially since my weekends spent on browsing Bilibili have also decreased significantly. This has led to another predicament: I now have material to write about, but these materials are only available when I’m busy, leaving me no time or energy to sort them out.
Nevertheless, the blog must go on, otherwise the accumulated experience and knowledge will remain unorganized.
Yes, I’m starting another series. On one hand, articles in a series appear more systematic and can be more helpful to beginners. On the other hand, it saves me from having to ponder too much on what to write next (which seems to be the real purpose).
Introduction to MQTT
MQTT is a very simple protocol, originally designed in 1999 by two IBM engineers, Andy Stanford-Clark and Arlen Nipper, for monitoring oil pipelines. It was designed for scenarios with limited bandwidth, lightweight, and very low power consumption. At that time, satellite bandwidth was just so small and painfully expensive.1
In modern society, although the cost of bandwidth has greatly decreased, there are still many scenarios where this protocol is needed, such as in smart homes (still part of IoT). Many small IoT devices rely on a button cell battery to function for years, making MQTT very suitable as an application layer transmission protocol.
In summary, MQTT is a client-server architecture publish-subscribe messaging transmission protocol. It is very lightweight, open, and simple, making it very easy to implement. These characteristics make it highly suitable for fields like machine-to-machine (M2M) and Internet of Things (IoT), which are limited by small memory and narrow bandwidth.2
IBM submitted version 3.1 to OASIS in 2013, and in 2014, OASIS made minor changes and released version 3.1.1.
In 2019, OASIS added many features to MQTT, such as better error handling, shared subscriptions, message content types, etc., and upgraded to version 5. These features will be discussed in dedicated chapters later on.
Hello World
First, you need an MQTT Broker. Install mosquitto … oh? You don’t know what that is? Okay, let’s try a simpler approach.
First, we can use some public ones, like China’s EMQ (Hangzhou Yingyun Technology Co., Ltd.) provides broker.emqx.io (I must advertise for domestic software here, their MQTTX client is the most user-friendly I’ve used so far, and the Broker’s features are also very powerful, I plan to specifically introduce server setup in a separate article).
Then, their MQTTX client, implemented in Electron, supports all platforms, just download and use.
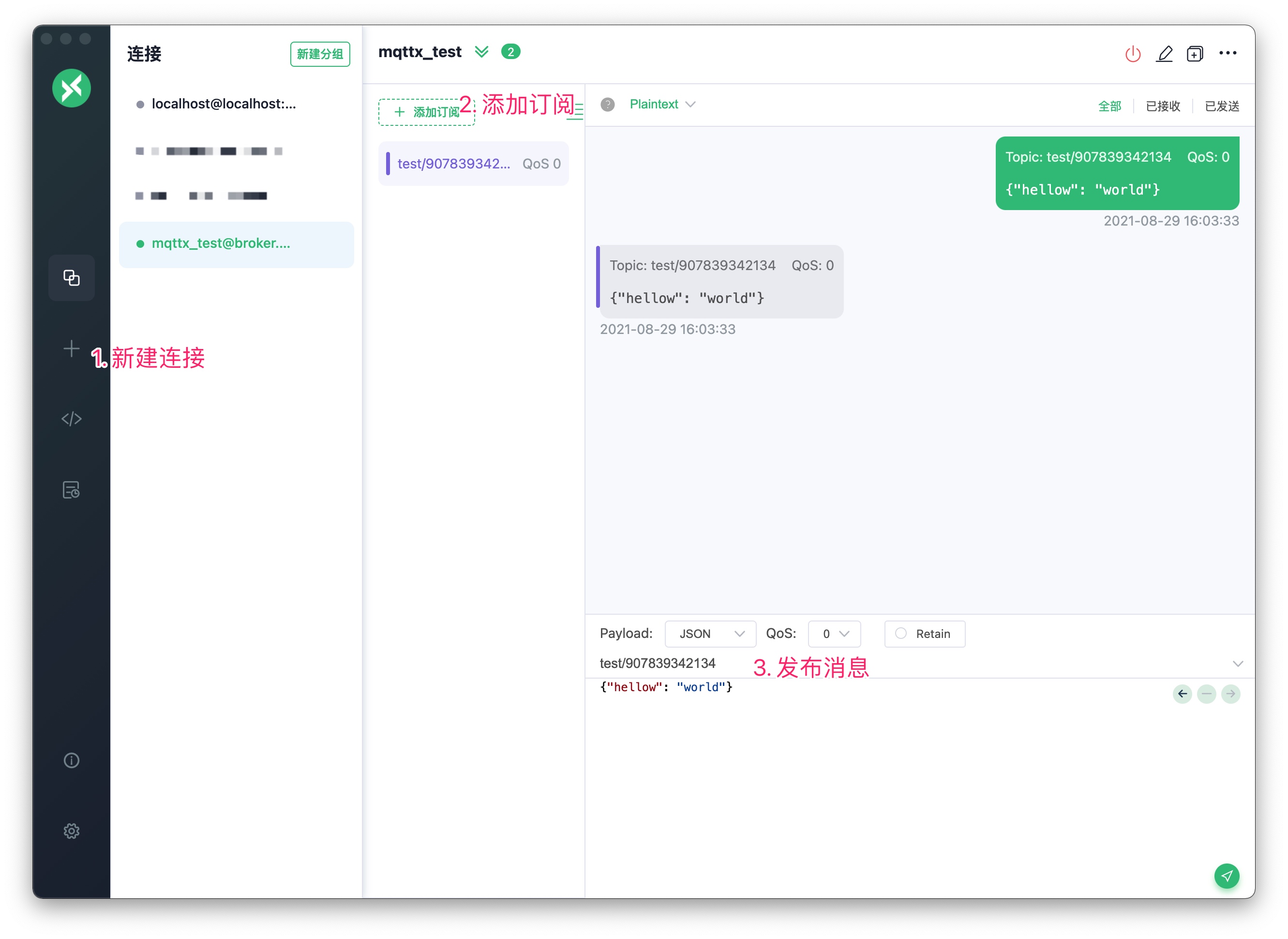
Open the MQTTX client, let’s start a simple test.
Click the + on the left sidebar to create a connection (this +, I think does not conform to interaction logic, as a creation button it should be a different level from other buttons, better placed together with new group creation);
A creation page will then pop up, fill in a name randomly, and click connect. If there are no network issues, you should be able to connect successfully (see, they know you’re lazy, all the details like Broker address and port are filled in for you, which is also very valuable for us making tech products, on how to let users start using the product with the lowest cost);
Now, let’s create a subscription, click add subscription on the page, in the popup dialog, fill in a somewhat random topic like test/907839342134 to avoid conflicts with others, as this is a public Broker, then click confirm.
Finally, let’s publish a message. In the bottom left corner, there’s an input box prompting you to enter a Topic, we enter test/907839342134, and in the content box below it, enter {"hello": "world"}, click the paper airplane below, and after sending, you will see that you have received the message you sent to yourself.
That’s it for now, a very simple introduction. In the next installments, I will introduce MQTT concepts, principles, and practical applications in more detail.
On branch masterUntracked files: (use "git add <file>..." to include in what will be committed) test.txtnothing added to commit but untracked files present (use "git add" to track)
即使进到 hidden_path 去查看 git status 也是一样。奇怪了,hidden_path/test.txt 这个文件哪里去了?
而当你用 ls 查看的时候,却发现那个文件还是存在的,但是它却在当前的 git 项目中「消失」了。你也可以测试看看,无论你往这个文件夹里面写任何文件,它都会「消失」。
好了,接下来,让我们把消失的文件找回来。
1 2
git rm --cached hiddle_path git add .
这时候再来看 git stauts,你就会发现消失的文件回来了:
On branch masterChanges to be committed: (use "git reset HEAD <file>..." to unstage) deleted: hiddle_path new file: hiddle_path/1.txt new file: hiddle_path/test.txt
这幅场景,简直就跟老板说下周要看到某个巨复杂的功能一样,大家刚刚听到后,估计也是一脸懵,同样会跟 NASA 那帮科学家一样束手无策。但话说回来,如果你能担当起这个责任,拿出方案来告诉老板为什么不可以做,或者如何去实现、并且做成做好了,那么你解决问题的能力就会越来越高,当然,同样越来越高的还会有你的位置与薪资待遇。
其实这就是所谓的高可用了,当你把程序部署到机器上去,它所面临的真实情况很可能就是你的测试用例所无法覆盖的,这时候就要用 Plan B 之类的冗余方式来保证高可用,不至于让程序再也无法启动,同时,安全边际就意味着你的服务能够承受较大的破坏,一个例子就是即使你 80% 的服务器都坏了,你依然能够用剩下 20% 的服务器来保证核心功能的正常使用。
Usage: hwclock [function] [option...]Time clocks utility.Functions: -r, --show display the RTC time --get display drift corrected RTC time --set set the RTC according to --date -s, --hctosys set the system time from the RTC -w, --systohc set the RTC from the system time --systz send timescale configurations to the kernel -a, --adjust adjust the RTC to account for systematic drift --predict predict the drifted RTC time according to --dateOptions: -u, --utc the RTC timescale is UTC -l, --localtime the RTC timescale is Local -f, --rtc <file> use an alternate file to /dev/rtc0 --directisa use the ISA bus instead of /dev/rtc0 access --date <time> date/time input for --set and --predict --delay <sec> delay used when set new RTC time --update-drift update the RTC drift factor --noadjfile do not use /etc/adjtime --adjfile <file> use an alternate file to /etc/adjtime --test dry run; implies --verbose -v, --verbose display more details -h, --help display this help -V, --version display version